
介绍
在计算机视觉领域,视觉变换器(ViT)通过采用自注意力机制彻底改变了图像处理,允许对图像进行非序列分析。ViT 有助于捕获复杂的模式和远程依赖性,这使得它们对于图像识别和对象检测等任务非常有价值。
Hugging Face 是尖端机器学习模型的中心,提供可轻松下载和实施的Vision Transformer 模型。然而,虽然 Hugging Face 文档提供了使用 Vision Transformer 获取图像表示的见解,但它缺乏针对特定任务微调这些模型的详细说明。这种信息差距给渴望利用 ViT 进行图像分类的从业者带来了挑战。
在本文中,我们将弥补这一知识差距。我将逐步指导您完成在 PyTorch 中微调 Hugging Face 中的 Vision Transformer 模型以进行图像分类的过程。读完本指南后,您将全面了解如何在基于 PyTorch 的图像分类项目中充分发挥 Vision Transformer 的潜力。
注意:本文中的所有脚本均在Google Colab笔记本中执行。
安装并导入所需的库
您需要安装 Hugging Face Transformers 库才能运行本文中的脚本。复制到剪贴板
! pip install accelerate -U
! pip install datasets transformers[sentencepiece]
以下脚本导入执行本文中的 Python 代码所需的 Python 库和模块。复制到剪贴板
from transformers import ViTModel, ViTFeatureExtractor, ViTModel, AdamW
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from datasets import load_dataset
import pandas as pd
import os
from PIL import Image
import random
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, classification_report, accuracy_score
from matplotlib import pyplot as plt
导入数据集
本文将指导您完成创建二元分类模型的过程。该模型使用面部图像作为输入,准确预测一个人的性别。您可以从 Kaggle 下载数据集。
数据目录如下所示:

我们将创建一个包含三列的 Pandas Dataframe:
- file_path:包含所有具有扩展名的图像的文件路径
.jpg。 - 类别:指定图像的文件夹名称,即
Female Faces或Male Faces. - class:如果图像位于
Male Faces文件夹中,则等于 1;如果图像位于Female Faces目录中,则等于 0。
这个DataFrame帮助我们快速检索图像和相应的标签进行训练。
以下脚本定义了create_image_dataframe()创建所需的 Pandas DataFrame 的方法。复制到剪贴板
def create_image_dataframe(data_dir):
file_paths = []
categories = []
classes = []
for category in os.listdir(data_dir):
category_path = os.path.join(data_dir, category)
if os.path.isdir(category_path):
class_label = 0 if category == r'Female Faces' else 1
for filename in os.listdir(category_path):
if filename.endswith('.jpg'):
file_paths.append(os.path.join(category_path, filename))
categories.append(category)
classes.append(class_label)
data = {
'file_path': file_paths,
'category': categories,
'class': classes
}
df = pd.DataFrame(data)
df = df.sample(frac=1).reset_index(drop=True)
return df
data_dir = '/content/male-and-female-faces-dataset/Male and Female face dataset'
image_df = create_image_dataframe(data_dir)
print(image_df.shape)
print(image_df.category.value_counts())
image_df.head()
运行上述脚本将返回以下输出:

输出显示该数据集由 5172 张图像组成,其中 2640 张图像包含男性面孔,2532 张图像包含女性面孔。您还可以看到生成的 Pandas DataFrame。
为图像创建 PyTorch 数据集
下一步是创建 PyTorch 数据集。尽管此步骤不是必需的,但它可以帮助您高效地批量训练模型,这可能至关重要,特别是当您在低内存系统上训练模型时。
我们的数据集将包含图像特征和相应的标签。要为 Vision Transformer 创建图像特征,您可以使用ViTFeatureExtractor. 该特征提取器将图像作为输入并返回可以传递给 Vision Transformer 的像素值。
以下脚本导入特征提取器。此处,该model_checkpoint变量存储已训练的 Vision Transformer 的检查点。您将使用相同的检查点来创建模型。
此外,如果 CUDA 可用,代码将配置为使用 GPU;否则,它默认在CPU上运行。复制到剪贴板
model_checkpoint = "google/vit-base-patch16-224-in21k"
image_processor = ViTFeatureExtractor.from_pretrained(model_checkpoint)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
接下来,我们定义一个将 Pandas DataFrame 转换为 PyTorch 数据集的方法。复制到剪贴板
class ImageClassificationDataset(Dataset):
def __init__(self, data_df, image_processor):
self.data_df = data_df
self.image_processor = image_processor
#self.max_length = 256 # set a fixed maximum length
def __len__(self):
return len(self.data_df)
def __getitem__(self, index):
image_path = self.data_df.iloc[index]['file_path']
image_val = Image.open(image_path)
if image_val.mode != 'RGB':
image_val = image_val.convert('RGB')
image_encodings = image_processor(image_val, return_tensors="pt")
labels = self.data_df.iloc[index][['class']].values.astype(np.float32)
return image_encodings, labels
我们将数据集分为训练集 (70%)、验证集 (30%) 和测试集 (30%):复制到剪贴板
train_df, temp_df = train_test_split(image_df, test_size=0.3, random_state=42)
val_df, test_df = train_test_split(temp_df, test_size=0.5, random_state=42)
最后,我们可以使用以下脚本将train_df、test_df和DataFrame 转换为 PyTorch 数据集。val_df为了批量迭代数据集,我们还创建DataLoader批量大小为 32 的相应对象。复制到剪贴板
train_dataset = ImageClassificationDataset(train_df, ViTFeatureExtractor)
test_dataset = ImageClassificationDataset(test_df, ViTFeatureExtractor)
val_dataset = ImageClassificationDataset(val_df, ViTFeatureExtractor)
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
创建用于微调的 PyTorch 模型
我们现在准备在数据集上微调 Vision Transformer 模型。为此,我们将创建一个模型类,它接受 Vision Transformer 编码器作为参数,并将编码器的输出传递给 5 个密集层。最后一个密集层由 1 个标签组成,因为我们计划预测一个二进制值,即 0 或 1。最终密集层中的 sigmoid 函数将返回 0 到 1 之间的值。复制到剪贴板
class ImageClassifier(nn.Module):
def __init__(self, num_labels, encoder):
super(ImageClassifier, self).__init__()
self.encoder = encoder
self.classifier = nn.Sequential(
nn.Linear(self.encoder.config.hidden_size, 500),
nn.ReLU(),
nn.Linear(500, 300),
nn.ReLU(),
nn.Linear(300, 100),
nn.ReLU(),
nn.Linear(100, 50),
nn.ReLU(),
nn.Linear(50, num_labels),
nn.Sigmoid()
)
def forward(self, input_values):
outputs = self.encoder(pixel_values = input_values)
pooled_output = outputs['last_hidden_state'][:, 0, :]
logits = self.classifier(pooled_output)
return logits
之后,我们将初始化 Vision Transformer 编码器并创建该类的对象ImageClassifier。我们还指定标签的数量(在我们的例子中为 1)以及损失函数和优化器。复制到剪贴板
# Set up the model, optimizer, scheduler, and loss function
num_labels = 1
encoder = ViTModel.from_pretrained("google/vit-base-patch16-224-in21k")
model = ImageClassifier(num_labels, encoder).to(device)
optimizer = AdamW(model.parameters(), lr=0.0001, betas=(0.9, 0.999), eps=1e-08)
criterion = nn.BCELoss()
随后,我们定义train()接受模型、训练和验证数据加载器、优化器、标准(损失函数)、设备和纪元数作为参数的方法。该train()方法训练模型并打印每批的损失。复制到剪贴板
# Define the training function
def train(model, train_loader, val_loader, optimizer, criterion, device, num_epochs):
best_accuracy = 0.0
for epoch in range(num_epochs):
model.train()
for i, batch in enumerate(train_loader):
image_encodings, labels = batch
pixel_values = image_encodings.pixel_values
pixel_values = pixel_values.squeeze()
pixel_values = pixel_values.to(device)
labels = labels.to(device)
optimizer.zero_grad()
logits = model(pixel_values)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
if (i+1) % 8 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {i+1}/{len(train_loader)}, Train Loss: {loss.item() :.4f}')
train_loss = 0.0
val_loss, val_accuracy, val_f1, _ , _ = evaluate(model, val_loader, device)
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
torch.save(model.state_dict(), 'best_model.pt')
print("========================================================================================")
print(f'Epoch {epoch+1}/{num_epochs}, Val Loss: {val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}, Val F1: {val_f1:.4f}, Best Accuracy: {best_accuracy:.4f}')
print("========================================================================================")
该train()方法还使用该方法打印验证集上的损失、准确度和 F-1 分数evaluate(),该方法在以下脚本中定义。最后,该train()方法在验证集上以最佳精度保存模型。复制到剪贴板
def evaluate(model, data_loader, device):
all_labels = []
all_preds = []
total_loss = 0.0
with torch.no_grad():
for i, batch in enumerate(data_loader):
image_encodings, labels = batch
pixel_values = image_encodings.pixel_values
pixel_values = pixel_values.squeeze()
pixel_values = pixel_values.to(device)
labels = labels.to(device)
optimizer.zero_grad()
logits = model(pixel_values)
loss = criterion(logits, labels)
total_loss += loss.item()
preds = (logits > 0.5).float()
all_labels.append(labels.cpu().numpy())
all_preds.append(preds.cpu().numpy())
all_labels = np.concatenate(all_labels, axis=0)
all_preds = np.concatenate(all_preds, axis=0)
loss = total_loss / len(data_loader)
accuracy = accuracy_score(all_labels, all_preds)
f1 = f1_score(all_labels, all_preds)
return loss, accuracy, f1, all_labels, all_preds
我使用以下脚本对模型进行了两个时期的训练。它已经给出了非常令人印象深刻的结果。复制到剪贴板
num_epochs = 2
train(model, train_loader, val_loader, optimizer, criterion, device, num_epochs)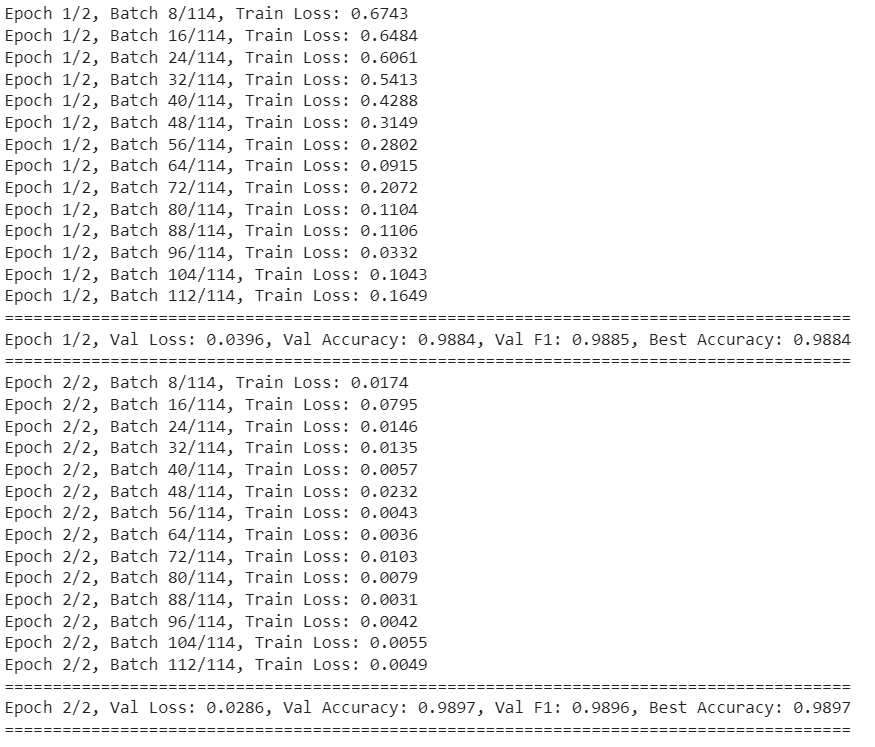
最后一步是在测试集上评估模型。为此,您可以导入我们使用训练保存的最准确的模型,并将其evaluate()与测试数据集一起传递给方法。复制到剪贴板
state_dict = torch.load('best_model.pt')
# Create a new instance of the model and load the state dictionary
num_labels = 1
model = ImageClassifier(num_labels, encoder).to(device)
model.load_state_dict(state_dict)
_, _, _, all_labels, all_preds = evaluate(model, test_loader, device)
print(classification_report(all_labels, all_preds))
print(accuracy_score(all_labels, all_preds))
输出显示我们在测试集上获得了 99.87% 的准确率。感人的?
结论
由于官方文档中缺乏详细信息,使用 PyTorch 模型训练 Vision Transformer 可能具有挑战性。本文提供了有关在 PyTorch 中通过 Hugging Face 微调 Vision Transformer 的分步指南。按照这些说明,您可以使用 Hugging Face 转换器创建图像分类模型。如果您有任何反馈或问题,请随时分享。